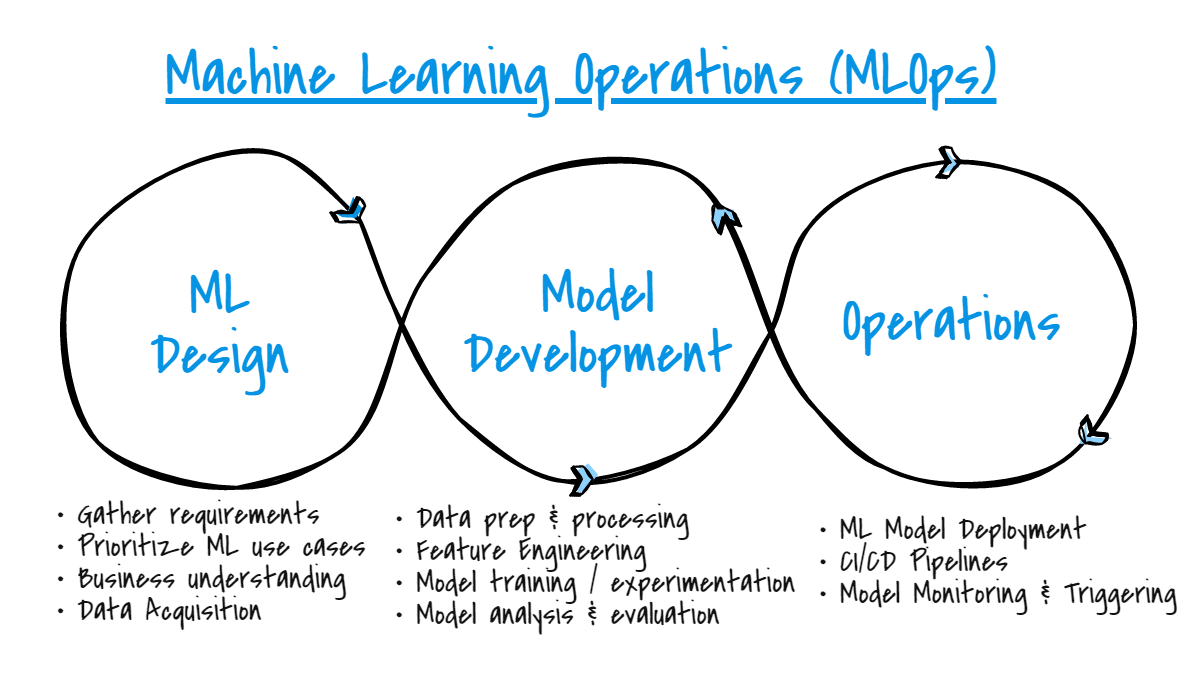
What is MLOps? An Introduction to the World of Machine Learning Operations

(Image source: Pratik D Sharma)
More than ever, AI and machine learning (ML) are integral parts of our lives and are tightly coupled with the majority of the products we use on a daily basis. We use AI/ML in almost everything we can think of, from advertising to social media and just going about our daily lives! With the prevalent use of these tools and models, it is essential that, as IT systems and software became a disciplined practice in terms of development, maintainability, and reliability in the early 2000s, ML systems follow a similar trend. The field focused on developing such practices is currently loosely defined under many different titles (e.g., machine learning engineering, applied data science), but is most commonly known as MLOps, or Machine Learning Operations.
What is MLOps?
So what is Machine Learning Operations? This paragraph from Pratik Sharma summarizes it best:
“MLOps is an approach to managing machine learning projects. It can be thought of as a discipline that encompasses all the tasks related to creating and maintaining production-ready machine learning models. MLOps bridges the gap between data scientists and operation teams and helps to ensure that models are reliable and can be easily deployed.”[1]
Simply put, MLOps is the marriage between the disciplines of machine learning and operations. While in previous years the greatest focus for most data scientists/machine learning practitioners was on research and development of state-of-the-art models, it has been increasingly necessary to apply an underlying methodology that allows for the systems supporting these models to be reliable and scalable to a large number of users (in practical terms, think data input). Not only do we want our models to make accurate predictions, we want to ensure that our models are available to anyone who seeks to use it.
The approach that the field of MLOps attempts to take is borrowed from the guidelines developed many years ago for software DevOps. MLOps aims to develop machine learning pipelines that meet the following goals:
-
The ML pipeline should follow a templated approach
-
The ML models should be reproducible (as much as possible) and iterable
-
The ML pipeline should be scalable
-
The ML pipeline should be automated from end-to-end
Why do we need MLOps?
We’ve talked a little bit about why MLOps is important for deploying large scale machine learning systems and what it tries to achieve. But why is the MLOps approach necessary? Could we not just store our models in larger and larger computing platforms that would allow it to handle huge amounts of data and traffic? The reality is a little more complicated.

Figure 1. Common components of an ML application (Image source: Google Cloud)
Figure 1 depicts some of the common components that are found as part of production-level ML systems. We can see that when it comes to creating usable models that are integrated with other software applications, there is a lot more to the system than the model, or ML, code. In fact, it’s often the case that the ML code is just a small part of the greater ecosystem. Take for example the serving infrastructure - without an interface to serve model predictions to client applications or users, our model predictions are essentially useless in an integrated system. As part of this infrastructure, there are many different things one must consider, including but not limited to: the methods which predictions are served, how/if common predictions are stored in a database or cache, and data security concerns.
It’s easy to see that without the proper frameworks and management processes in place, these systems can quickly get unwieldy. The problem of large scale ML systems can’t simply be handled by adding more compute power.
Machine Learning Pipelines

Figure 2. Stages of a Machine Learning pipeline (Image source: Yashaswi Nayak)
Before we go about discussing how we would orchestrate machine learning pipelines that meet the goals of MLOps, let’s examine at a high level what a traditional ML pipeline looks like. As can be seen in Figure 2, an ML project can be broken down into five general stages [2]:
-
Scoping: Scoping the problem we want to solve in the context of ML, and defining the design requirements for the system that addresses the problem
-
Data Engineering: Establishing data collection methods, data cleaning, EDA, and feature engineering/transformation steps necessary to get the data into the format used as input to the model
-
Modeling: Training the model(s), performing error analysis and comparing against baselines
-
Deployment: Packaging up the final model to serve model predictions in production
-
Monitoring: Monitoring and tracking both the model and serving performance and detecting any errors or data drift
These latter four stages are essential to helping us develop and build a machine learning pipeline that takes us through the entire lifecycle of a model. Performing these stages manually is a great start if we are only concerned with creating a single model, but in most cases there is eventual need to iterate and develop new models. And this is where the principles of MLOps can help us iterate quickly and effectively.
Applying MLOps Principles to an ML Pipeline
Let's walk through how we can apply MLOps guidelines to our ML pipeline above, and how these will help us convert our pipelines to robust ML lifecycles.
1) The ML pipeline should follow a templated approach
First and foremost, if our pipeline isn’t built in such a manner that is conducive to each stage flowing onto the next, then there isn’t much we can do in terms of orchestration. From the design stage, our pipelines should be created so that each stage can interact with the next without much friction or additional interactions. If we can create a template for the pipeline, we can help to reduce many unnecessary headaches trying to get our system to work in the first place.
Luckily, there are many established frameworks for designing these pipelines, and by using one we can be assured that many of the things we would traditionally need to consider are handled for us. There are many existing frameworks that help us manage these details, such as MLFlow or KubeFlow. All of the big cloud providers (Google Cloud, AWS, Microsoft Azure) also provide their own array of services for developing such pipelines that are contained in such a way to allow for repeatable development.

Figure 3. The AWS ecosystem offers and supports a wide range of ML services (Image source: AWS)
2) The ML models should be reproducible (as much as possible) and iterable
As part of our pipeline, we should be able to easily determine the datasets and parameters that were used when we trained our models. Creating reproducible pipelines with proper versioning and tracking of metadata allows us to recreate the different steps that led to a specific model being trained (with the understanding that there are many non-deterministic models that have some degree of randomness associated with the training, and may deviate from iteration to iteration). Without this reproducibility, we lose insight into how our models were created and makes it difficult to triage potential issues. On top of that, a reproducible pipeline enables us to iterate on older versions of models by keeping all the steps of the pipeline the same, and just changing the necessary parameters (e.g., the dataset) to create new model versions.
3) The ML pipeline should be scalable
As both the input and output of the models increase (both from a dataset and usage standpoint), we want our ML pipeline to be able to scale against this increased demand. Our pipelines should not only be able to allocate more compute power to train larger models or models on larger datasets, but should also be able to handle greater traffic and usage from end-users and clients. Without this scalability, our models could take too long to train, or worse yet no longer be powerful enough to handle the data size. On the service side, increased traffic could bring down our application altogether. Luckily, many of the commonly used frameworks mentioned previously easily incorporate this dimension directly as part of their design patterns.
4) The ML pipeline should be automated from end-to-end
Now that we have a pipeline that follows a robust framework and is reproducible, iterable, and scalable, we have all the necessary ingredients to automate our pipeline. Creating automated pipelines is the crux of MLOps. With automated ML pipelines, we can continuously integrate, train and deploy new versions of models quickly, effectively, and seamlessly without any manual intervention. This can be extremely useful in the world of constantly changing data where our ground truth may fluctuate rapidly.
Although not covered in this blog post, the level of automation defines the maturity of the MLOps process, and can be classified into three distinct levels [3]:
-
MLOps level 0: Manual process
-
MLOps level 1: ML pipeline automation
-
MLOps level 2: CI/CD pipeline automation
Where to go from here
Although this was a surface level summary, I hope this blog post helped to introduce some of the basic concepts of MLOps. If you have not already, I hope reading through this post encourages you to think about the vast landscape that is Machine Learning Operations, and the importance that it serves in establishing stable machine learning systems. As a field that has been quickly gaining momentum over the last few years, the fast development of new ideas makes it an exciting place to be. And as our reliance on large-scale ML systems continues to grow, I believe it will become more and more an essential part of a data scientist’s tool kit for years to come.
References
-
Sharma, Pratik. “10 Best MLOps Tools in 2022.” Pratik Sharma, 5 March 2022, https://www.pratikdsharma.com/10-best-mlops-tools-in-2022/
-
Nayak, Yashaswi. “A Gentle Introduction to MLOps. A guide to the world of Machine… | by Yashaswi Nayak.” Towards Data Science, https://towardsdatascience.com/a-gentle-introduction-to-mlops-7d64a3e890ff
-
“MLOps: Continuous delivery and automation pipelines in machine learning.” Google Cloud, 7 January 2020, https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning