
We often read about the many new advancements being made in the field of Natural Language Processing (NLP). Each month, leading organizations release new models that seem like magic to us, such as models that can write it’s own code based on user prompts [1] or are able to help answer our queries when we use Google Search [2]. Large AI research groups like OpenAI and Google spend many years and pour millions of dollars into research to perfect these models. These sophisticated models can contain up to billions of parameters (GPT-3, [3]) and can require many hours and expensive computing infrastructure to train. When all is said and done, these models feel out of reach and similar models impossible to attain. However, with just a little work, you too can learn to use and apply these state-of-the-art models to the problems you are trying to solve. In this blog post, I will briefly introduce and cover how to use the renowned Hugging Face code libraries, specifically the Transformers library, which does most of the heavy lifting for us and allows us to easily plug and play with these bleeding edge models.

Figure 1. A screen capture from OpenAI’s live demo of their Codex model. In the live demo, Codex auto-generates the code (shown in the right hand panel) for a simple space video game based on user prompts (shown in the text box in the bottom left).
About Hugging Face
Hugging Face is a large open-source AI community, most commonly known for its easy-to-use, deep learning libraries. Launched in 2016 and named after the smiling emoji, HuggingFace started out as a chatbot designed to be a friendly and upbeat virtual companion designed to try and detect emotion from messages, photos, emojis and keep things light with users. As a result of wrapping complex NLP models into simple functions for its own purposes, it quickly turned into one of the most popular Python libraries for machine learning practitioners. Hugging Face is highly compatible with many other packages such as NumPy and Pandas, and has model ports for both PyTorch and TensorFlow deep learning frameworks (which I will go into a little more further below). Hugging Face is so popular that over 5,000 organizations use it, including those that originally built the models available in the library, such as Google and Facebook!
Although it has many packages, its crown jewel is the Transformers library which, “provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio” [4]. The library is so-called because it contains models that are based on the popular transformer network architecture, which uses the mechanism of self-attention in its encoder-decoder layers to allow these models to learn contextual meaning in language and retain better long-term dependencies between words [5]. This wide-spread adoption of the transformer architecture was the main reason behind the rapid development of the enormous, state-of-the-art language models that we see today.
Using the Transformers library, you can quickly download and use the pretrained versions of these large language models and apply them to downstream tasks of your choosing. Similar to other fields in machine learning, it has been shown that there is great efficacy in using transfer learning (where a large, generalized model that has been trained on one task is used for prediction in other tasks) for NLP tasks [6].
Using the Transformers Library
In this simple example, I will demonstrate how to use the Transformers Library using a transformer model known as BERT (Bidirectional Encoder Representations from Transformers) [7] to identify the appropriate interpretation of the word ‘bank’ based on the context-based embedding (also known as the vector-space representation of the word). One of the strengths of using transformer models like BERT is the ability to distinguish between different homonyms based on context, which was one of the major downfalls of using traditional static embeddings such as Word2Vec [8] and GloVe [9].
Start by installing the “transformers” library as you would normally in Python. Below is an example using the “pip” package installer.

Figure 2. Install the “transformers” library using the “pip” package installer.
Now that we have the essential library installed, we can import the packages we will need. Note that although the default port for Hugging Face models is written in PyTorch, I will be using the Tensorflow version of the BERT model. While PyTorch is more often used in academic research, Tensorflow is probably the more widely used framework in practice and can be slightly easier to learn. However, both libraries have more or less the same functionalities and can therefore be used effectively for deep learning.

Figure 2. Import the libraries to be used. NOTE: If you do not already have them installed, both “numpy” and “tensorflow” packages will need to be installed as well.
Above, we’ve imported both the BERT Tokenizer and the Tensorflow (TF) plugin of the model from the “transformers” library. The tokenizer is used to convert our word inputs into word-part tokens so that the inputs can be understood by the model [10].
We’re done with the setup, so let’s take a look at the primary sentence we will be looking at. Our homonym of interest is ‘bank’ at the end of the sentence, "I deposited 10000 dollars in the bank”. We want to see if our model can properly distinguish the appropriate word embedding for ‘bank’ such that it understands that ‘bank’ in this context refers to the financial institution, as opposed to the banking of an airplane or a river bank.
Let’s use the BertTokenizer to convert the sentence into tokens that BERT can understand. In the image below, we see how the sentence is converted into tokens. The prefix ‘##’ in the fourth token indicates that it is a continuation of the previous tokens, as in the original sentence.

Figure 3. Tokenization of the sentence "I deposited 10000 dollars in the bank”.
We now have the tokens, but we still need another step before inputting this sentence into the model. As in most cases, deep learning models based on neural networks need numeric input in order to be trained and make predictions, so we need a way to encode the text as numbers. Luckily, our tokenizer handles this encoding process as well!
Below, we see that the text sentence inputs have been encoded, with each number representing a token. You may have noticed that there are now eleven numbered tokens as opposed to the nine text tokens: this is a result of the tokenizer adding a class token (101) and sentence separator (102) to the beginning and end respectively. For brevity, I will not cover the specifics of this, but more details can be found in the original paper [7].

Figure 4. Encoding of the sentence "I deposited 10000 dollars in the bank”.
The tokenizer can also encode multiple sentences at the same time, also known as batch encoding. Let’s encode the other example sentences that we will compare our primary sentence with. The idea is that we want BERT to be able to distinguish between the different homonyms of ‘bank’ across the various sentences and determine which is most similar to the meaning of ‘bank’ in our primary sentence. The other example sentences are:
-
"I will need to bring my money to the bank tomorrow."
-
"I had to bank into a turn."
-
"The shoe that I dropped washed up onto the bank."
If all goes well, BERT will be able to tell us that ‘bank’ in our primary sentence is most similar to the last example sentence.
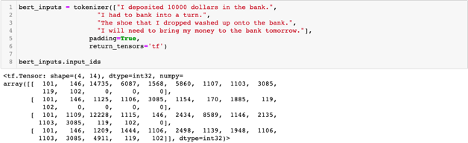
Figure 5. Batch encoding for the four example sentences
If you look carefully, you may notice the ‘0’ tokens that weren’t there previously. These tokens are what is known as “padding”, which is used to ensure that all the sentences are the same length (equal in length to the longest sentence).
Next, let’s actually go and get the model to output the word embeddings. Amazingly, this only requires two lines of code! The first line downloads our desired model (in this case, the base version of BERT that is able to handle cased words), and the second line gets the outputs. This perfectly illustrates how easy it is for anyone to use these complex models.

Figure 6. Download the ‘bert-base-cased’ model and get the embedding outputs for the four example sentences.
We can use cosine similarity [11] to compare the similarity of two word vector embeddings between 0 and 1. The function below will calculate the cosine distances between a list of vectors and print out the resulting similarity matrix.


Figures 7 & 8. Function to calculate cosine similarities between a list of vectors and the list positions of the word ‘bank’ in each sentence to calculate the cosine similarities.
Finally, we can take a look at the outputs and see if our initial conjecture was correct. As expected, when observing the cosine similarities, we see that the word ‘bank’ in sentences 1 and 4 have the highest similarity, while the similarities between all other homonyms are lower.

Figure 9. Cosine similarity matrix between the word ‘bank’ in each of the four example sentences. ‘bank’ in sentences 1 and 4 have the highest similarity, with a value of 0.93.
Endless Possibilities...
With just a few lines of code, we were able to easily apply one of the state-of-the-art NLP models in BERT to our own use case. Although this is just a simple example, I hope it helps demystify the magic behind these powerful models and gives you a taste of the potential that is at your fingertips through the amazing Hugging Face library. If you are interested in learning more, Hugging Face provides plenty of example notebooks [12], or if you are curious to see applications in research, please feel free to check out my research project on “Reducing Gender Bias During Fine-Tuning of a Pre-Trained Language Model” [13].
Acknowledgements
Thank you to Mark Butler and Joachim Rahmfeld, as well as the other instructors for DATASCI W266: “Natural Language Processing with Deep Learning”, for the great instruction and material on which this blog was heavily based.
Bibliography
-
“OpenAI Codex.” OpenAI, 10 August 2021, https://openai.com/blog/openai-codex/.
-
Nayak, Pandu. “Understanding searches better than ever before.” The Keyword, 25 October 2019, https://blog.google/products/search/search-language-understanding-bert/.
-
Brown, Tom B., et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165, (2020).
-
“Transformers.” Hugging Face, https://huggingface.co/docs/transformers/index.
-
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems., (2017).
-
Petroni, Fabio, et al. “Language models as knowledge bases?.” arXiv preprint arXiv:1909.01066, (2019).
-
Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805, (2018).
-
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781, (2013).
-
Pennington, Jeffrey, et al. “Glove: Global vectors for word representation.” Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)., (2014).
-
“What is Tokenization | Tokenization In NLP.” Analytics Vidhya, 26 May 2020, https://www.analyticsvidhya.com/blog/2020/05/what-is-tokenization-nlp/.
-
Jurafsky, Dan, and James H. Martin. Speech and Language Processing, 2nd Edition. Pearson Prentice Hall, 2008.
-
“Transformers Notebooks.” Hugging Face, https://huggingface.co/docs/transformers/notebooks.
-
“Reducing Gender Bias During Fine-Tuning of a Pre-Trained Language Model.” Github, https://github.com/stemlock/w266_final_project/blob/master/W266_Final_Report_NF_ST.pdf.